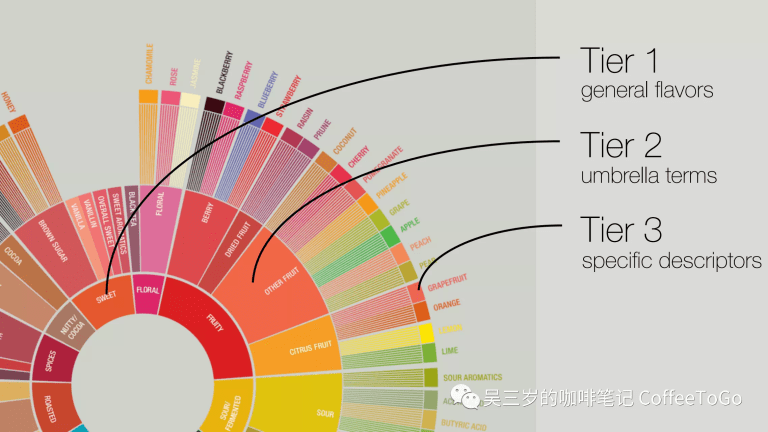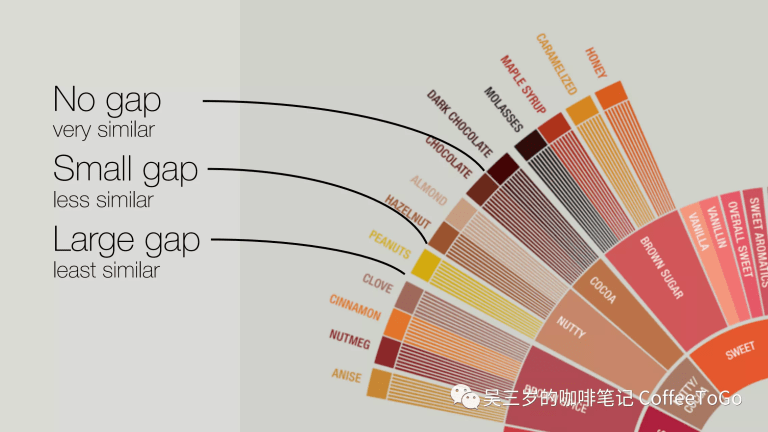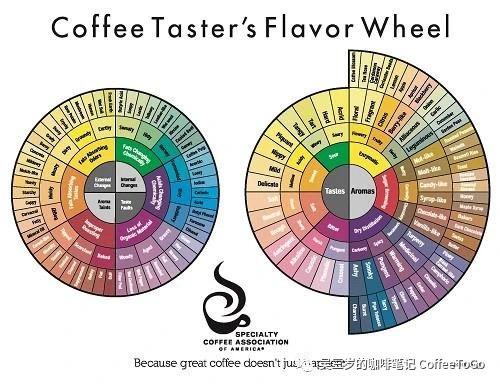
(1995版咖啡風味輪,圖源SCA)
是的,就是那個出版已經超過25年的舊版咖啡風味輪。
新版風味輪於2016年發布,距今已經5年。如果這個科學家們大量研究得來的寶貴成果沒辦法用到實處,將是相當可惜。
那麼,是新版風味輪的研發出了什麼問題?抑或是我們還沒有真正了解它?
既然新版風味輪從科研中來,那想要純熟地使用它,就要先回到那篇原始文獻中。
科研文獻雖然複雜,但三歲的這篇文章盡量簡單。不需要計算,更不必緊張,睡前看看更加健康~
舊版風味輪為什麼好用?
回到1995年,時任SCAA執行總監的泰德·林格(Ted Lingle)發布了第一版咖啡風味輪,為他那本奠定行業規範的《咖啡杯測手冊》(The Coffee Cupper’s Handbook)提供了清晰有力的補充。
而在此之前,全球咖啡人對於咖啡中的基本風味並沒有達成共識。大家不清楚咖啡中有哪些風味,或者知道一些風味但卻對不知道它的來源以及好壞,更不用說風味的類別以及從屬關係了。
如果不同地方的咖啡從業者沒有辦法對風味產生共識,也就沒有共同語言,廣東人叫“雞同鴨講”。這顯然成為了在全球推廣精品咖啡時的一大障礙。
所以,可以想像泰德先生在看到1984年出版的葡萄酒風味輪時,那種“就是它了”的雀躍,以及跨越產業、超越時間的共鳴——這是一個梳理了風味產生的邏輯,再將其分門別類,可以供全產業使用可視化工具。

(葡萄酒香氣輪,圖源網絡)
1995版風味輪經久不衰,主要是因其從咖啡本身的特點出發,描述了種植、處理、烘焙、萃取以及感官的五個規律。我們自上而下觀察正向風味輪右半邊的芳香組,會發現香氣的排列對應:
• 香氣物質生成的階段,即酶促化的產物主要在種植和生豆加工處理的階段產生,焦糖化和乾餾化反應的物質分別在烘焙的一爆和二爆後產生;
• 咖啡烘焙的過程,即從淺烘焙到深烘焙,香氣依次以酶促化、焦糖化以及乾餾化反應的產物為主導;
• 萃取程度由低到高時, 香氣物質進入杯中的次序,即酶促化反應的物質更早進入杯中;
• 香氣化學物質的分子量,分子量越小的化學物質越靠上,即越容易揮發也越容易被感知。
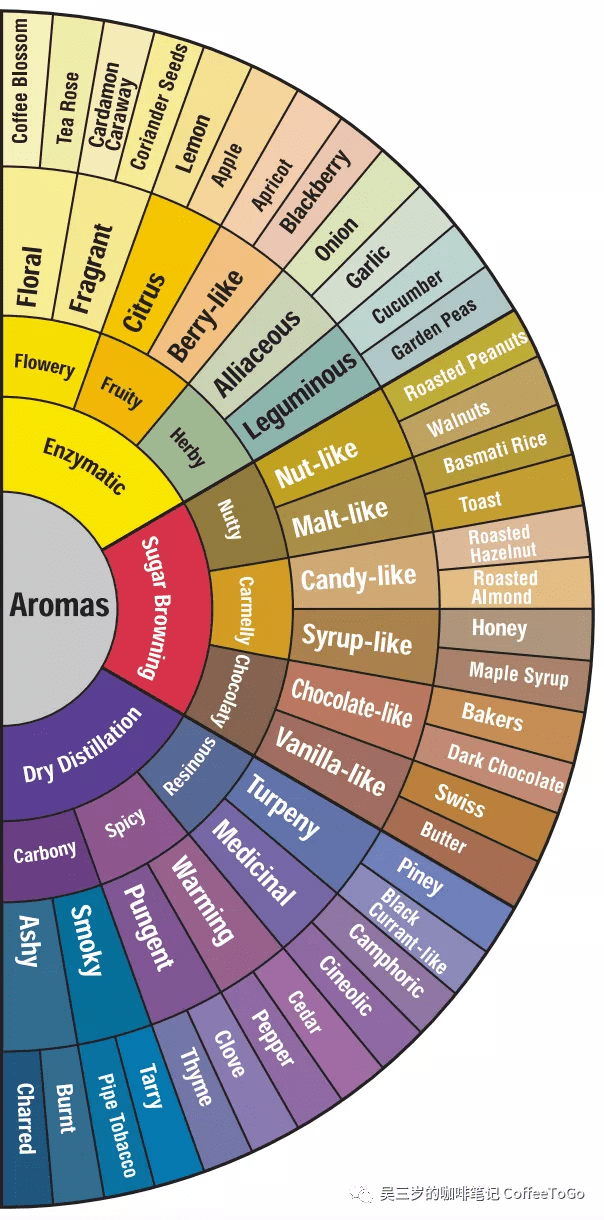
(1995版咖啡風味輪中的香氣部分,圖源網絡)
如此一來,推廣風味輪不僅促進了共同語言的建立,還讓大家了解到了咖啡科學中的底層邏輯。
新版風味輪有哪些創新?
可是,比對舊版咖啡風味輪和葡萄酒風味輪可以輕易發現,前者是左右兩個輪,後者則是一個輪。
為什麼咖啡風味輪不是一個輪呢?
另外,對於舊版咖啡風味輪而言,左邊是瑕疵風味,右邊是味道和正向香氣。左右兩個輪雖然都是咖啡的風味,但彼此之間卻割裂開了。
我們能夠了解瑕疵和正向風味是對立的兩面,可是到底有多對立?
在舊版風味輪中, “花香(flowery)”和“果香(fruity)”相鄰,可以理解這兩者都是酶促化反應帶來的香氣。但與此同時,“花香”也和“酸味(Soury)”相鄰,那這又該如何理解它們之間的關係呢?

(1995版咖啡風味輪中的“花香”及周邊風味屬性,圖源三歲)
風味是香氣和味道的結合。舊版風味輪或許可以從生物、物理和化學的角度上解釋部分咖啡的規律,比如香氣之間的聯繫,味道之間的聯繫,但卻沒辦法在可視化的層面解釋香氣和味道的關係,瑕疵風味和正向風味的聯繫。
SCAA(彼時還沒和SCAE聯合為SCA)敏銳地註意到了這點,於2016年發布了全新的咖啡風味輪。
新版風味輪為什麼值得再三研究?是因為它背後是科學家們嚴謹的分析和對進一步建立咖啡產業共同語言的渴望。
SCAA首先和世界咖啡研究所(World Coffee Research,簡稱WCR)、堪薩斯州立大學和德州農工大學的感官科學家們以及行業代表們合作,測試與分析全球13個國家105個不同咖啡樣本的風味,選出了最具代表性的110種,彙編成了《感官詞典》(Sensory Lexicon),作為新版風味輪的基礎研究。鮮為人知的是,該詞典還在一年後更新了第二版,新增了24個新詞。

(第二版《感官詞典》,圖源網絡)
不過,科學家們在編制新版風味輪時剔除了不易測量的觸感類詞彙,如“澀的(Astringent)”、 “質地(Texture)”和“口腔觸感(Mouthfeel)”,最後剩下99個詞。
有了關於咖啡風味大量數據後,該如何分析它們之間的深層關係並組織為一個統一的可視化工具呢?
SCAA找到了加州大學戴維斯分校的Jean-Xavier Guinard教授和莫利·斯賓塞(Molly Spencer)博士。
Jean-Xavier Guinard教授何許人也?
簡單檢索Google Scholar,他的H指數為42,即有42篇論文被引用過42次,且在“消費者科學(consumer science)”領域引用量排名第一,是一名一流的科學家。

(Jean-Xavier Guinard教授的Google Schlor專頁,圖源網絡)

(Google Schlor中“消費者科學”領域學者的引用量排名,圖源網絡)
兩人先是召集了29名沒有正式受過咖啡感官訓練,但有長期喝咖啡的習慣且了解描述性分析的成員,以及43名來自咖啡行業的專家。這些成員之間沒有討論,也不會接受進一步的訓練,這是為了保持他們對於風味之間關係的獨立判斷,以客觀反映人對於咖啡風味的感知。
在正式測試中,他們會在一個線上軟件對《感官詞典》中的詞彙進行分類,如下圖:

(測試人員為風味分類時的界面,圖源原始論文)
像在這位測試員的認知中,他認為“黑莓(Blackberry)”、“樹莓(Raspberry)”、“藍莓(Blueberry)”和“草莓(Strawberry)”都是包含在“莓果類果香(Fruity,berry)”風味之下的,而“莓果類果香(Fruity,berry)”又包含在“果香(Fruity)”之下。
如此一來,得到了一位測試人員對於風味之間關係的認知,並在有關係的一對風味之間標註“1”,沒關係則標註“0”,如下圖:

(某位測試人員的部分結果,圖源原始論文)
然後,再統計所有測試人員對於風味關係的認知,如下:
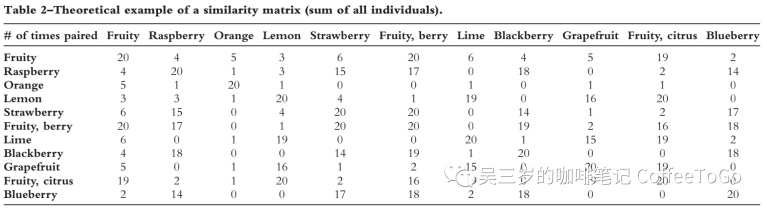
(部分測試結果的統計,圖源原始論文)
分數越高,也就意味著越多測試人員認為那對風味之間是有聯繫的。
那麼,該如何整合所有測試人員的數據呢?科學家們用到了一種稱之為“凝聚層次聚合分析法(agglomerative hierarchical clustering ,簡稱AHC)的方式,將一盤散沙般的數據按照它們之間聯繫的緊密程度進行分類,逐步歸為更大的類別,直至到達指定條件,最終得到結果如下:
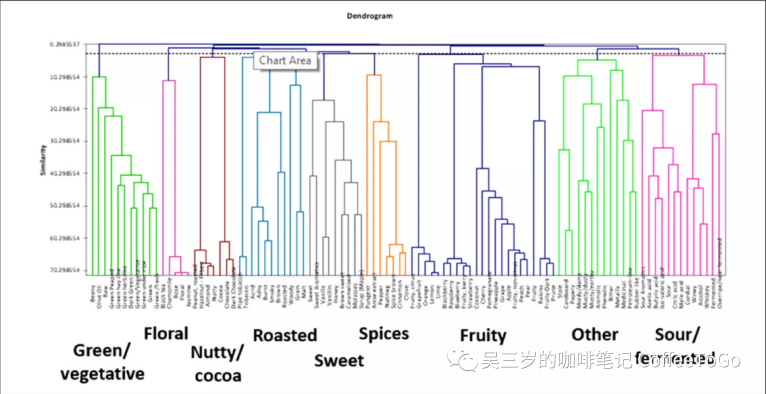
(AHC結果統計,圖源原始論文)
我們簡單拿一個組別出來看,相同顏色的圈指示同一個風味類別。

(部分測試結果的統計,圖源原始論文)
這樣一來,弄清楚了一個大類之下的風味聯繫。
那麼,大類之間的關係又如何?在風味輪上應該按照什麼順序來排列呢?科學家們拿出了另外一種方法——多維尺度分析法( multidimensional scaling,MDS),將各種風味之間的多維聯繫轉化為二維平面上的聯繫,如下圖:

(MDS結果的統計,圖源原始論文)
我們可以清晰看到“花香(Floral)”和“其他(Others)”分居兩極,說明測試人員認為它們的差異很大,實際上“其他”就約等於舊版風味輪中的瑕疵,而“花香”和“果香”、“甜(Sweet)”相鄰,即這兩大類是比較類似的。
雙管齊下,一個基於感官科學的風味輪就此誕生。
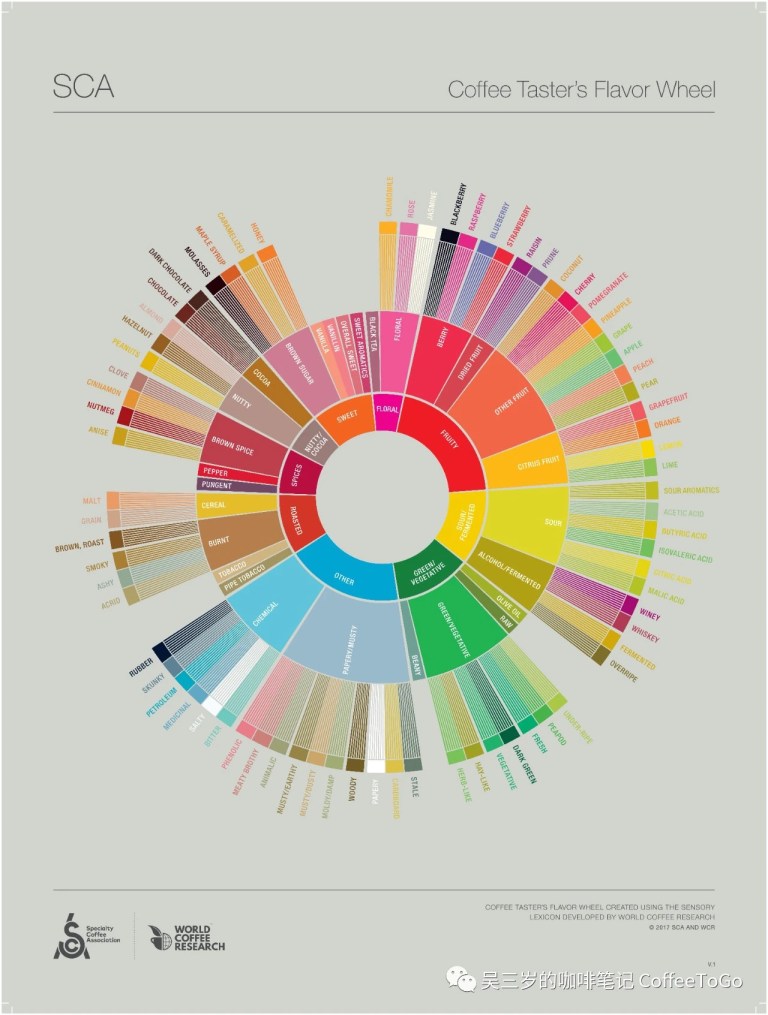
怎麼用新版風味輪?